Change Data Extract Job Options for a Data Extract Job in QC
In the QC module, you can reprocess a Data Extract Job and, before doing so, set the QC Reprocess Options for the Data Extract job.
To set the Reprocess Options for a Data Extract Job:
-
At the bottom of the Document List window, click
 in
the QC Functions toolbar to open the Options for Data Extract dialog box.
in
the QC Functions toolbar to open the Options for Data Extract dialog box.
The Options for Data Extract Job dialog displays.

-
Set the options as appropriate, when finished, click OK.

Note: After you change the Data Extract Job options, when you reprocess selected files in the Documents List window in the QC module, the files will be reprocessed using the modified Data Extract Job options.


 Data Extract Options
Data Extract Options
The following steps describe how to set the options available for creating a Data Extract Job.
Set the General Options
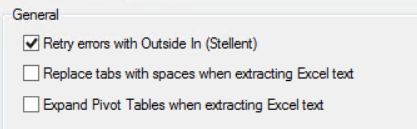
Retry errors with Outside In (Stellent) - Used to image Microsoft Office (Excel, Word, and/or PowerPoint) documents. The Outside In (Stellent) option:
- Allows for faster and more consistent generation of images on the first pass
- Reduces the amount of time spent manually QCing these document types
When this check box is selected, only Outside In (Stellent) is used to process images; the Microsoft related options are grayed out by default. Full metadata is extracted and time zone imaged output reflects the time zone handling options configured for the Data Extract Job. All files processed by Outside In (Stellent) receive the Stellent Processed flag in QC.
The processing output differs when using Outside In (Stellent) to view and image documents. However, the QC applied flags, metadata, and optional summary reports will be similar if processing is done without Outside In (Stellent). Other processing options, including Flex Processor processing options, are respected when using Outside In (Stellent).
Replace tabs with spaces when extracting Excel text - When this check box is selected, the extracted Excel text will look similar to the following:
Column A Column B
Value1 Value2
The column data is separated by a space rather than a tab (which can be, for example, the equivalent of five spaces). Therefore, if the check box is cleared, then the column data of the extracted Excel text is separated by a tab (five spaces) and would look similar to the following:
Column A Column B
Value1 Value2
Expand Pivot Tables when extracting Excel text - By default, this check box is cleared. If pivot tables exist, then they will be expanded when this check box is selected. A flag is also set in QC to indicate that the Pivot table exists in the worksheet.
Set the OCR Options for a Specific Data Extract Job

|
|
Note: If you are setting Case (Project) Level options, OCR and Time Zone Handling options are defined on the Common Options tab because Discovery Jobs and Data Extract Jobs use the same OCR and Time Zone Handling options. For more information about setting options at the Case (Project) level, see Create a New Case (Project). |

The OCR Settings available for Data Extract Jobs are outlined in the following table.
|
Option |
Description |
|||
|---|---|---|---|---|
|
OCR images as necessary |
Select this check box to OCR images. Images will be OCRed for indexing/language identification if necessary. The OCR text obtained from the image is then passed on to dtSearch for indexing. The OCR will be indexed and available to be searched on in the Flex Processor. |
|||
|
OCR PDF documents |
PDFs with no embedded text: perform OCR before indexing or language identification. PDF pages with embedded text (text-behind) will have text extracted. Comments on a PDF file are also extracted.
|
|||
|
OCR PowerPoint Documents |
Select this check box to perform OCR on Microsoft PowerPoint files during Data Extract to get text from embedded content in the slides. This results in slower speeds for PowerPoint files, but more accurate text extraction. |
|||
|
PDF page character threshold |
Select a PDF page character threshold and indicate a value. The default value is 25 characters. If the value is less than 25, eCapture sends the page to be OCRed. If necessary, enter a different value. |
|||
|
Minimum average OCR confidence [1-100] |
The level range settings are from 1 to 100. The default is 50. The OCR Confidence Level is the average percentage of confidence for each document, for all pages within a document on which OCR was performed. Success or failure of a document for flagging is based on the average confidence level of the document. If the average confidence level is below the selected threshold, the document is flagged in QC with the OCR Low Confidence Flag.
|
|||
|
OCR Languages |
eCapture includes multi-language OCR capability. The QC document will contain the original OCR languages that were selected for the Data Extract Job. A valid multi-language OCR license must be available in order to modify the original selected languages, if necessary. To reserve a portion of the multi-language OCR licenses for QC and to keep the Worker from consuming all available licenses, use the Multi-Language OCR License slider located in the Controller System Options dialog box. Click OCR Languages to display the Language OCR dialog box. After selecting the languages, click OK to close the dialog box. The selected languages display in the OCR Languages field. Place the mouse pointer on the OCR Languages field to display a tool tip that lists all the selected languages that were not visible in the OCR Languages field. The OCR Languages field is a read-only field. Click
Click here to view some English is the only language that is selected by default. The more languages that are selected, the lower the confidence level will be for correctly identifying the languages in a document.
|
Set the Appropriate Option for Lotus Notes
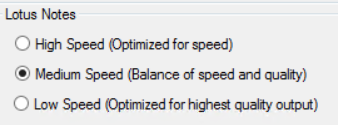
- High Speed (Optimized for speed)
- Medium Speed (Balance of speed and quality)
- Low Speed (Optimized for highest quality output)
Set the Appropriate Option for Time Zone Handling

- Convert all times to UTC
- Specify Time Zone
For more information about Time Zone Handling, see How eCapture Handles Dates and Time Zones.
|
|
Note: If you are setting Case (Project) Level options, OCR and Time Zone Handling options are defined on the Common Options tab because Processing and Data Extract Jobs use the same OCR and Time Zone Handling options. For more information about setting options at the Case (Project) level, see Create a New Case (Project). |
Related Topics